
Decision trees and random forests
MELODEM data workshop

Gini impurity
For classification, “Gini impurity” measures split quality:
\[G = 1 - \sum_{i = 1}^{K} P(i)^2\]
\(K\) is no. of classes, \(P(i)\) is the probability of class \(i\).

First split: right node
Consider splitting at flipper length of 206.5: Right node:

First split: left node
Consider splitting at flipper length of 206.5: Left node:

First split: total impurity
Consider splitting at flipper length of 206.5: Impurity:

Regression trees
Impurity is based on variance:
\[\sum_{i=1}^n \frac{(y_i - \bar{y})^2}{n-1}\]
\(\bar{y}\): mean of \(y_i\) in the node.
\(n\): no. of observations in the node.

Survival trees
Log-rank stat measures split quality (Ishwaran et al. 2008):
\[\frac{ \sum_{j=1}^J O_{j } - E_{j}}{\sqrt{\sum_{j=1}^J V_{j}}}\] \(O\) is observed and \(E\) expected events in the node at time \(j\). \(V\) is variance.

Keep growing?
Now we have two potential datasets, or nodes in the tree, that we can split.
Do we keep going or stop?

Stopping conditions
We may stop tree growth if the node has:
Obs <
min_obsCases <
min_casesImpurity <
min_impurityDepth =
max_depth

Your turn
Suppose
min_obs= 10min_cases= 2min_impurity= 0.2max_depth= 3
Which node(s) can we split?

Split the left node
The left node can be split.
The right node cannot, since impurity on the right is <
min_impurity

Finished growing
The left node can be split.
After splitting the left node, all nodes have impurity <
min_impurity.If no more nodes to grow, convert partitioned sets into leaf nodes

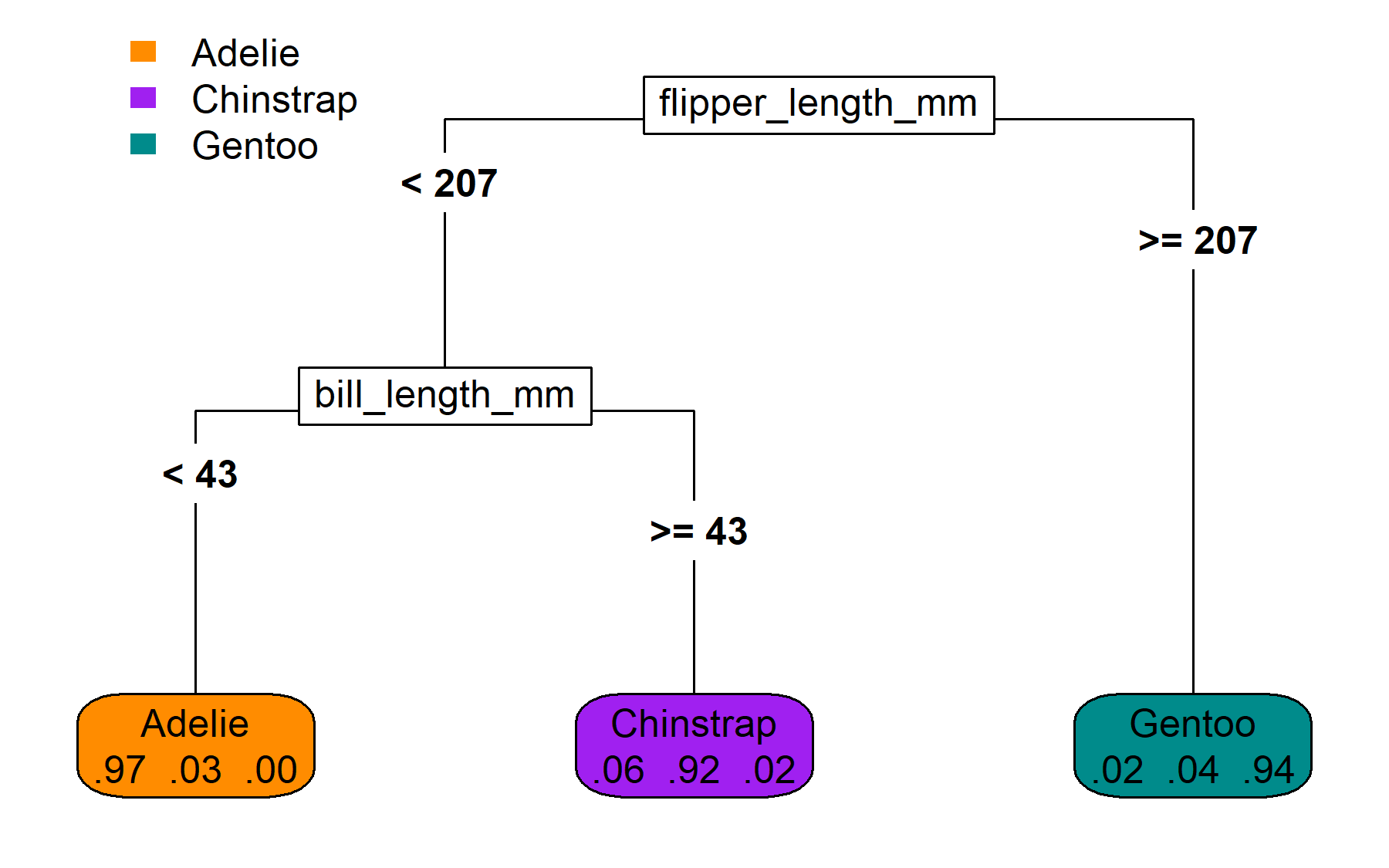
From partition to flowchart
The same partitions, visualized as a binary tree.
As a reminder, here is our ‘hand-made’ leaf data
| Adelie | Chinstrap | Gentoo | |
|---|---|---|---|
| leaf_1 | 0.02 | 0.04 | 0.94 |
| leaf_2 | 0.06 | 0.92 | 0.02 |
| leaf_3 | 0.97 | 0.03 | 0.00 |
A single traditional tree is fine

A single randomized tree struggles

Five randomized trees do okay

100 randomized trees do great

500 randomized trees - no overfitting!

How to get out-of-bag predictions

Grow tree #1

Store its predictions and denominators

Now do tree #2

Accumulate predictions and denominator

Variable importance
First compute out-of-bag prediction accuracy.
Here, classification accuracy is 96%

Variable importance
Next, permute the values of a given variable
See how one value of flipper length is permuted in the figure?

Variable importance
Next, permute the values of a given variable
Now they are all permuted, and out-of-bag classification accuracy is now 61%

Variable importance
Rinse and repeat for all variables.
For bill length, out-of-bag classification accuracy is reduced to 63%
